Deduplicación de datos
La deduplicación de datos es un sistema que reduce el tamaño del backup, excluyendo los bloques de información duplicados. En grandes empresas, las máquinas virtuales de Hyper-V o VMware, contienen datos duplicados, como puedan ser modelos repetidos de máquinas virtuales que, o tienen el mismo sistema operativo o los mismos archivos. La deduplicación de bloques de datos reduce el tamaño del backup, guardando solamente los bloques de datos únicos, reemplazándolos con las referencias de los que ya existen.
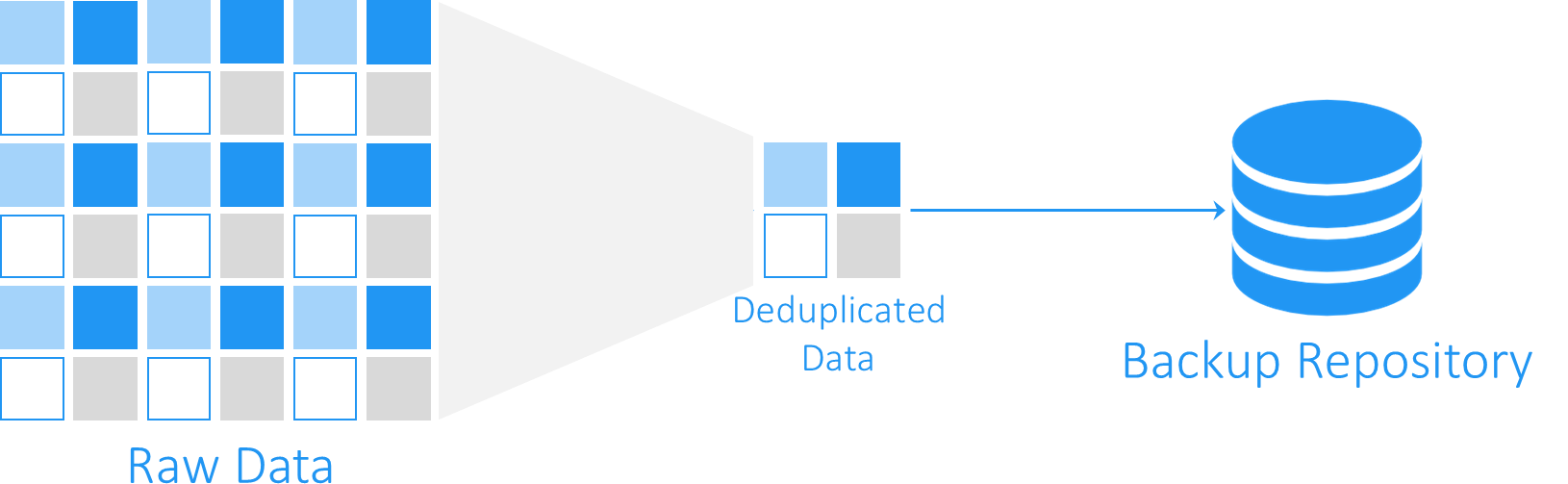
Nakivo deduplica automáticamente todos los backup de un repositorio. Esto significa que todos los bloques de datos se tienen en cuenta, incluso si almacenamos copias de seguridad de máquinas de Hyper-V, VMware e instancias EC2 de Amazon en el mismo repositorio. En la configuración del programa, esta opción viene habilitada por defecto, pero si quiere usar un dispositivo específico para deduplicar los datos como EMC Data Domain, puede desconectar la opción en la interfaz.
La deduplicación le proporciona reducir el tamaño del backup hasta en un 30%, por ejemplo, tiene 10 máquinas virtuales en Windows 2016 Server que ocupan 10Gb cada una. Siendo el total de datos unos 100Gb, solo se copiarán en el repositorio del backup los 10 Gb que pertenecen a los datos del sistema operativo de una de las máquinas, ya que todas tienen la misma información de arranque.
Este ahorro de almacenamiento en el disco, le permitirá crear más puntos de restauración por backup. Además, un espacio más reducido no requerirá tanta inversión en discos y todo lo que conlleva el mantenerlos (electricidad, servicio de aire acondicionado para que no se sobrecalienten…). Nakivo le da las herramientas necesarias para tener la información sus máquinas de Hyper-V y VMware protegida y optimizada en el respositorio.